
L’élagage des arbres décisionnels est une technique essentielle en apprentissage automatique, visant à optimiser les modèles d’arbres décisionnels en réduisant le surapprentissage et en améliorant la généralisation aux nouvelles données. Dans ce guide, nous explorerons l’importance de l’élagage, ses types, sa mise en œuvre et sa signification dans l’optimisation des modèles d’apprentissage automatique.
Qu’est-ce que l’élagage des arbres décisionnels ?
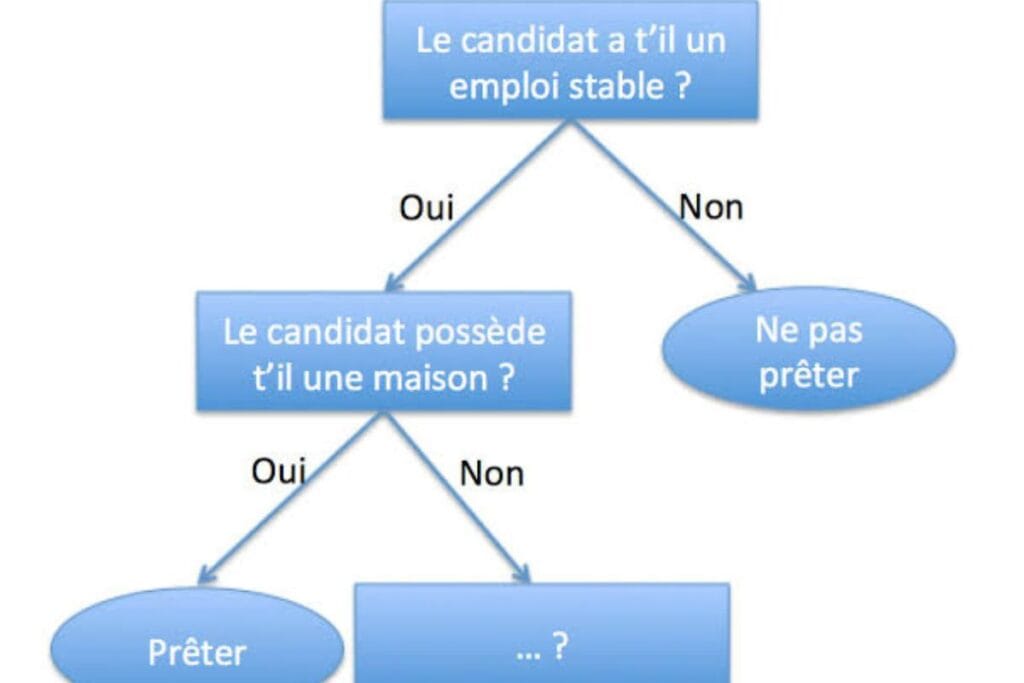
L’élagage des arbres décisionnels est une méthode utilisée pour éviter que les arbres ne mémorisent les données d’entraînement. Son objectif est de simplifier l’arbre en supprimant les parties qui n’apportent pas de pouvoir prédictif significatif, ce qui améliore sa capacité à généraliser aux nouvelles données. En éliminant des nœuds indésirables, on obtient un modèle plus rapide, plus précis et plus efficace.
Types d’élagage des arbres décisionnels
Il existe deux types principaux d’élagage : pré-élagage et post-élagage.
- Pré-élagage (Arrêt précoce) : Cette technique arrête la croissance de l’arbre avant qu’il ne devienne trop complexe. Les techniques courantes incluent :
- Profondeur maximale : Limite la profondeur de l’arbre.
- Nombre minimum d’échantillons par feuille : Définit un seuil minimal pour chaque feuille.
- Nombre minimum d’échantillons pour une séparation : Spécifie le nombre d’échantillons requis pour diviser un nœud.
- Caractéristiques maximales : Restreint le nombre de caractéristiques considérées pour la séparation.
- Post-élagage (Réduction des nœuds) : Après la croissance complète de l’arbre, cette méthode consiste à retirer des branches pour améliorer la généralisation. Techniques courantes :
- Élagage par coût-complexité (CCP) : Attribue un coût aux sous-arbres en fonction de leur précision et complexité.
- Élagage par erreur réduite : Supprime les branches qui n’affectent pas significativement l’exactitude globale.
- Diminution de l’impureté minimale : Élagage si la diminution de l’impureté est inférieure à un seuil donné.
Mise en œuvre de l’élagage en Python
Pour illustrer l’élagage, nous utiliserons le jeu de données breast_cancer de la bibliothèque sklearn. La technique de pré-élagage est appliquée avec le DecisionTreeClassifier, utilisant le critère d’impureté de Gini. L’exemple suivant montre comment créer et évaluer un arbre décisionnel :
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, plot_tree
import matplotlib.pyplot as plt
Chargement et séparation des données
X, y = load_breast_cancer(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.2, random_state=42)
Entraînement du modèle
model = DecisionTreeClassifier(criterion= »gini »)
model.fit(X_train, y_train)
Précision avant élagage
accuracy_before_pruning = model.score(X_test, y_test)
print(« Précision avant élagage : », accuracy_before_pruning)
Pourquoi l’élagage est-il important ?
L’élagage joue un rôle vital dans l’optimisation des modèles d’arbres décisionnels pour plusieurs raisons :
- Prévention du surapprentissage : L’élagage simplifie la structure de l’arbre, évitant ainsi la mémorisation des données d’entraînement.
- Amélioration de la généralisation : Un arbre élagué capture mieux les motifs sous-jacents, ce qui améliore ses performances sur des données non vues.
- Réduction de la complexité du modèle : Cela rend le modèle plus facile à interpréter et diminue les exigences computationnelles.
- Interprétabilité accrue : Des arbres plus simples sont plus faciles à comprendre, ce qui est crucial dans des domaines comme le diagnostic médical.
- Accélération de l’entraînement et de l’inférence : Moins de nœuds signifie des prédictions plus rapides sans perte de précision.
Conclusion
L’élagage des arbres décisionnels est fondamental pour optimiser les modèles en évitant le surapprentissage et en améliorant la généralisation. Pour des ensembles de données plus petits, l’élagage postérieur est couramment utilisé, tandis que le pré-élagage est plus efficace pour des ensembles de données plus volumineux. En maîtrisant ces techniques, on peut construire des modèles d’apprentissage automatique plus robustes et interprétables.